扩展:PingCAP案例
背景
卡思数据所有产品都是基于大数据分析计算的,分布式的服务架构业务场景下,各服务节点的压力是可控的,压力集中在了数据库处。
除了日常业务产生的数据外,每天会有5到6小时的时间用来处理基础数据,数据量大且时间短。
两年多时间,卡思数据的数据架构经过了多次调整,目前稳定使用的 MySQL + TiDB。
1. MySQL + MongoDB
MySQL存储业务相关数据,因为直接面向用户,对事务的要求很高,但在海量数据存储方面偏弱,单表数据超过1000万或10G性能就会急剧下降。
MongoDB存储最小单元的基础数据,MongoDB有更好的写入性能,保证了每天数据爬取存储速度;对海量数据存储上,MongoDB内建的分片特性,可以很好的适应大数据量的需求。
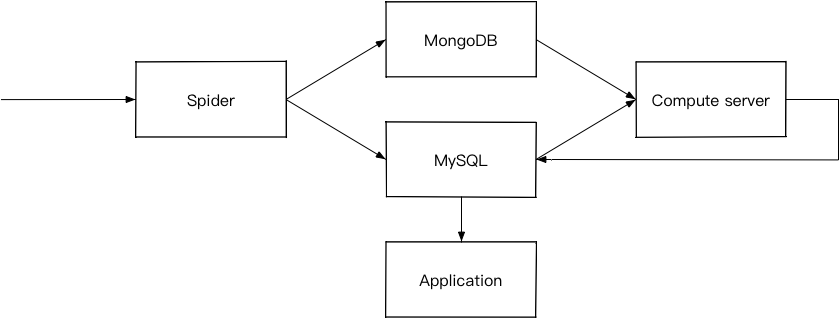
但是随着业务发展,暴露出一些问题:
- MySQL 在海量数据下,查询性能难以满足要求,并且扩展能力偏弱,如果采用分库分表方式,需要对业务代码进行全面改造,成本非常高。
- MongoDB 对复杂事务的不支持,前台业务需要用到数据元及连表查询,当前架构支持的不太友好。
2. HybirdDB for MySQL
阿里云数据库(PetaData)是同时支持海量数据在线事务(OLTP)和在线分析(OLAP)的HTAP关系型数据库,实际上是基于 MySQL Sharding 的数据架构。
因为在不少业务场景存在需要即时计算的情况,所以直接将原有的MySQL与MongoDB进行了合并,使用了阿里云的PetaData,以下为PetaData的架构图:
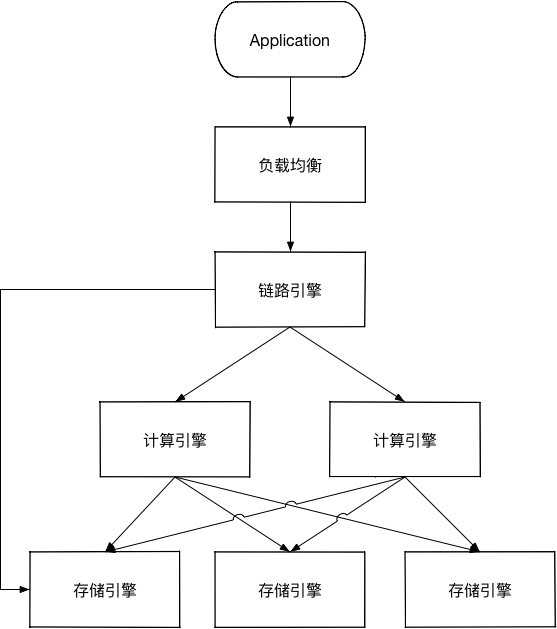
- 链路引擎:用户的SQL经过链路引擎解析、优化之后,生成相应的执行计划:对于简单查询场景,直接将计算推至存储节点执行,若查询较复杂则直接由计算引擎生成相关计划树并执行。
- 计算引擎:在存储引擎执行之前,生成SQL执行计划,下推至存储引擎;聚合从各存储节点查询返回数据。
- 存储引擎:存储实际数据库的数据,分布式节点、分区存储,通过hash key进行分区。
存储引擎的架构如下:
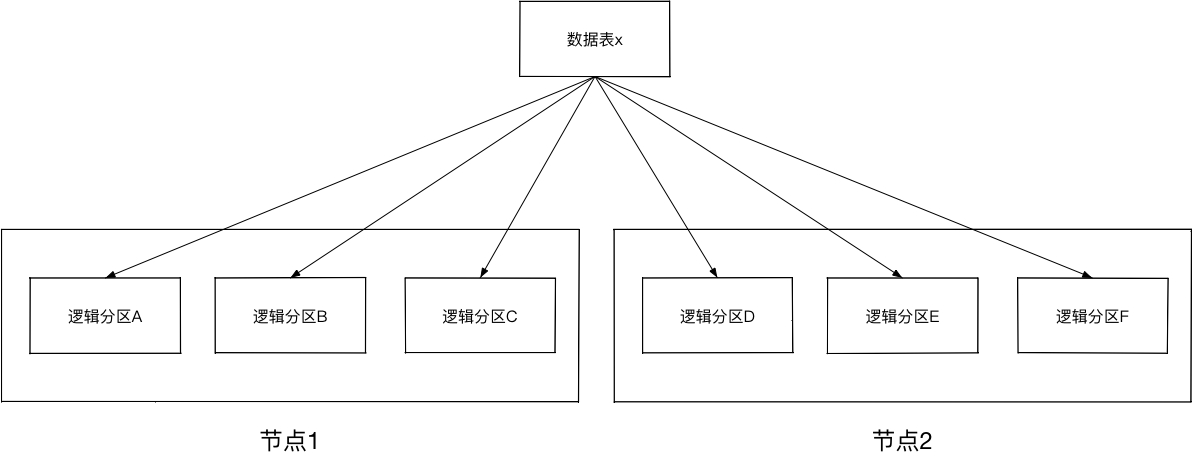
试用一段时间后,出现以下问题:
- 复杂语句导致计算引擎拥堵,阻塞所有业务;
- 连表查询性能低下,网络IO出现瓶颈;
- DDL较慢,下发至节点后易出现死锁。
3. MySQL + TiDB
在经历了痛苦的传统解决方案的折磨后,在做了大量调研及对比后,卡思数据最终选择了TiDB作为数据仓库及业务数据库。
TiDB结合了传统的 RDBMS 和 NoSQL 的最佳特性,高度兼容MySQL,支持无限的水平扩展,具备强一致性和高可用性,100% 支持标准的 ACID 事务。
卡思数据目前配置了两个32C64G的TiDB、三个4C16G的PD、4个32C128G的TiKV。数据量大约 60亿条、4TB左右,每天新增数据量大约5000万,单节点QPS峰值为3000左右。
由于数据迁移不能影响线上业务,卡思数据在保持继续使用原数据架构的前提下,使用mydumper、loader进行数据迁移,并在首轮数据迁移完成后使用 syncer 进行增量同步。
卡思数据部署了数据库监控系统 (Prometheus/Grafana)来实时监控服务状态,可以非常清晰的查看服务器问题。
由于TiDB对MySQL的高度兼容性,在数据迁移完成后,几乎没有对代码做任何修改,平滑实现了无侵入升级。
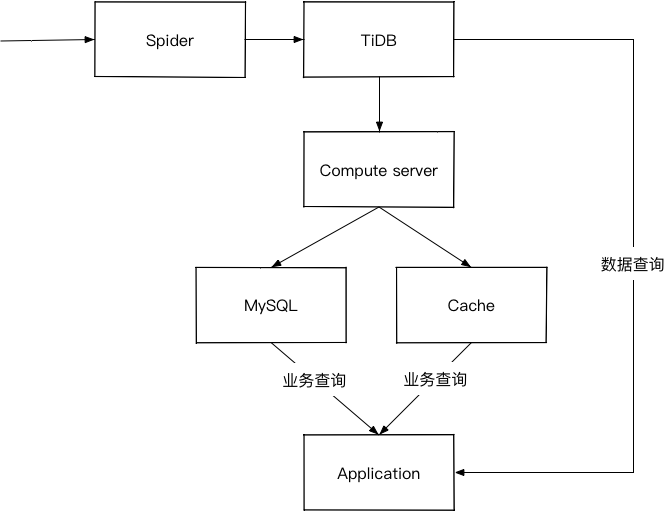
目前卡思数据的架构如下:
未来
目前的卡思数据已全部迁移至TiDB,但对TiDB的使用还局限在数据存储上,可以说只实现了OLTP。卡思数据准备深入了解OLAP,将目前一些需要实时返回的复杂查询、数据分析下推至TiDB。既减少计算服务的复杂性,又可增加数据的准确性。